
웹은 인터넷에 연결되어 있는 컴퓨터를 통해 모든 사람들이 자유롭게 정보를 공유 및 검색할 수 있는 서비스를 말한다. 우리는 저번에 HTML로 만든 웹사이트를 온라인 공간에 올리려고 한다. 정확히 말하면 인터넷에 올려서, 인터넷에 접속해 있는 모든 사람들이 검색할 수 있게 만들려고 한다. 어떻게 해야 할까?
목차
1. 서버와 클라이언트
2. 웹의 역사
3. 일반인이 서버를 구하는 법
1. 서버와 클라이언트
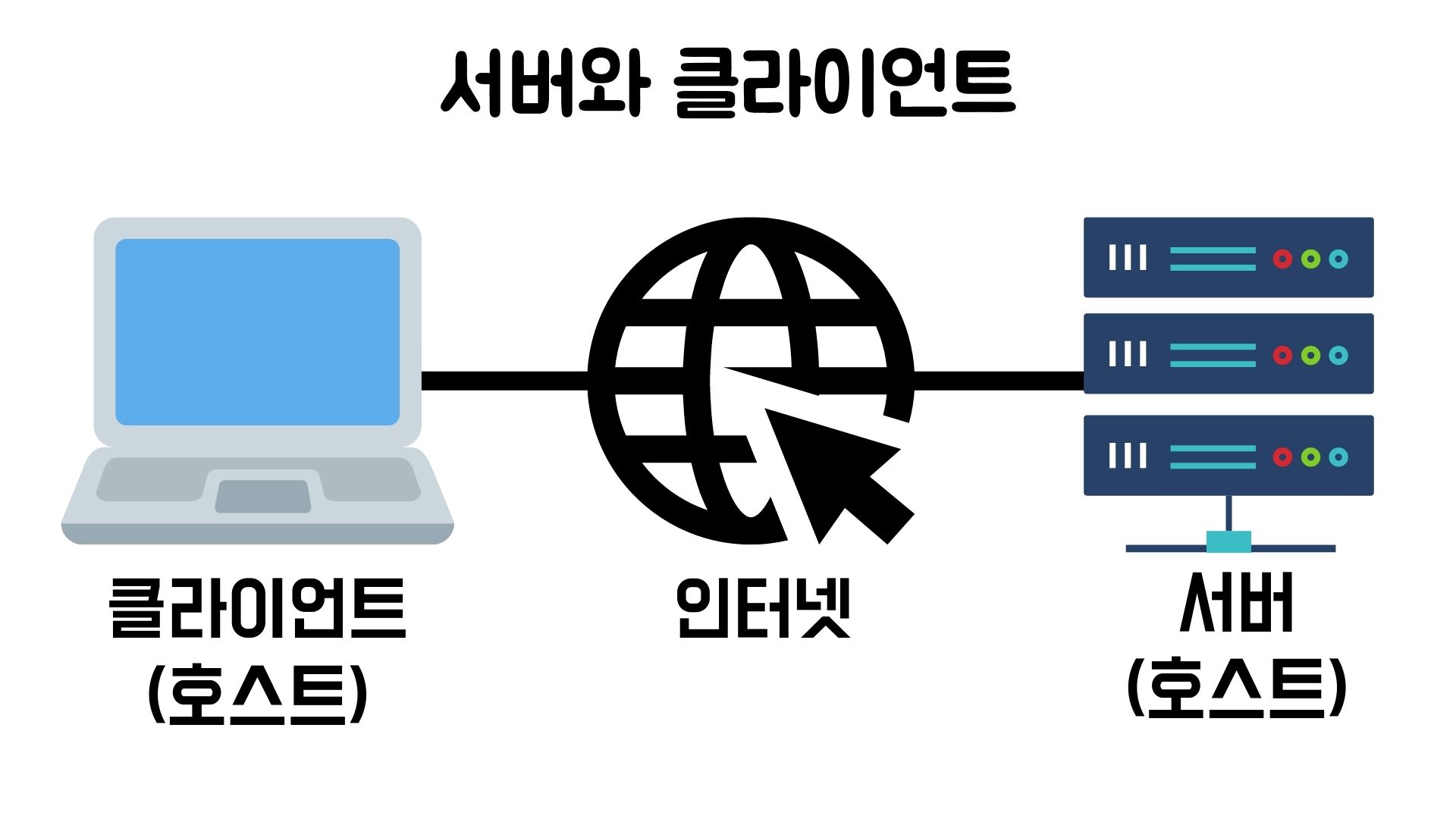
답은 매우 간단하다. 나는 내가 만든 HTML파일을 인터넷에 연결된 어떤 기계에 저장을 한다. 인터넷에 연결된 기계 장치를 전문용어로 호스트(Host)라고 한다. 달리 말하면, 이 호스트에 내가 만든 파일을 저장한다. 그리고 다른 사람들은 인터넷에 연결된 자신의 컴퓨터로 그 파일에 접근한다.
여기서 사람들에게 파일(혹은 큰 범위에서는 데이터)을 전송하는 이 호스트를 서버라고 한다. 그리고 그 서버에 접근하는 호스트를 클라이언트(Client)라고 한다. 클라이언트란 말은 손님, 서버는 손님에게 서비스를 제공하는 사람이라는 의미로 일상대화 에서도 쓰인다. 모든 호스트들은 서버나 클라이언트가 될 가능성을 갖고 있다.
서버와 클라이언트(생활코딩): https://opentutorials.org/course/3084/18890
2. 웹의 역사

큰 윤곽은 잡혔다. 서버에다가 HTML파일을 올리면 된다. 그리고 클라이언트는 그 파일의 위치를 찾아서 그 파일을 불러오면 된다. 지금에서는 당연한 기술이 1990년 대 출시 당시엔 첨단기술이었다. 이 역사에 대해 조금 구체적으로 들어가보자. 이제 웹의 핵심기술에 대해서 알아볼 때다. 웹의 핵심기술은 3가지로 정리된다. 하이퍼텍스트(Hypertext), HTTP(HyperText Transfer Protocol), URL(Uniform Resource Locator)이다. 이 3가지 중에서도 또 한 가지 제일 중요한 것을 고르자면, 하이퍼텍스트이다.

웹은 팀 버너스 리(Tim Berners Lee)라는 사람이 1990년 초에 만들었다. 버너스 리는 유럽 입자 물리 연구소에서 일하고 있었는데, 다른 사람들과 정보를 공유하는데 큰 어려움을 느꼈다. 당시에는 컴퓨터도 있었고 인터넷도 존재하긴 했다. 다만 인터넷은 소수의 사람들만 이용하는 통신망이었고, 안타깝게도 당시 연구소의 컴퓨터들은 인터넷이 연결 되어있지 않았다. 각기 다른 컴퓨터들이 각기 다른 정보들을 가지고 있었고, 심지어 각기 다른 아이디로 로그인도 했어야 했다.
버너스 리는 그래서 당시 떠오르는 기술인 인터넷에 관심을 가졌다. 그래서 인터넷에 연구소 컴퓨터를 연결하려고 했다. 근데 이 사람은 여기서 더 나아가 기존의 인터넷을 그대로 이용하지 않고 더 좋은 방법을 떠올렸다. 하이퍼 텍스트라는 개념을 문서에 적용하는 것이었다. 하이퍼텍스트는 텍스트에 다른 파일로 순식간에 이동할 수 있는 링크를 거는 기술이다. 하이퍼텍스트가 들어간 파일이 등장한 것이다.

당시의 인터넷은 지금으로 치자면 인트라넷(사내망)과 같았다. 서버와 클라이언트 개념은 당연히 존재했다. 업무를 위해서 인터넷을 통해 텍스트도 주고받을 수 있었고, 여러 문서도 전송할 수 있었다. 근데 생각을 해보자. 예를 들어 위키피디아를 찾다가 본문에 나온 public domain이란게 뭔지 궁금해졌다.
근데 public domain이 하이퍼텍스트가 아니라고 하자. 심지어 당시에는 웹브라우저 란 것도 없었고, 검색창이란 것도 거의 없었다. 그러면 이것이 뭔지 알기 위해서는 그냥 누군가에게 직접 물어보거나 누군가가 내부 서버에 이에 대한 정보를 올렸는지 직접 뒤져보는 수밖에 없다. 후자의 경우엔 서버에 쌓인 파일이 많으면 많을수록, 내가 들여야 할 노력도 많아진다. 마치 모르는 단어가 나왔는데, 이것의 뜻을 찾으려고 무작정 사전을 펴서 일일이 읽는 것과 같다.

만약 하이퍼텍스트를 이용한다면 어떻게 될까? 서버를 일일이 뒤지는 일을 생략하고, 순식간에 바로 찾아볼 수 있다. 즉 정보를 탐색하는 시간을 없애는 것이다. 버너스 리는 개념으로만 있던 하이퍼 텍스트 문서를 구현하기 위해서 HTML이라는 언어를 만들었고, HTML파일을 클라이언트와 서버 사이로 전송하기 위한 규약인 HTTP를 만들었다. 그리고 서버(더 넓게는 네트워크)에 담긴 파일의 위치을 나타내는 방식을 하나로 통합했다. 그 방식을 우리는 URL(Uniform Resoure Locator)이라고 부른다. 그리고 HTML파일이 담기는 최초의 웹서버도 만들고, HTML파일을 열람할 수 있는 WWW(World Wide Web)이라는 최초의 웹 브라우저도 만들었다. 정말 대단하신 분이다.

그런데 보통의 경우 이런 문제가 있지 않을까? 내가 찾고 싶은 정보가 서버에 아예 없는 경우다. 정보량이 많아지려면 이 네트워크에 참여할 사람들 역시 많이 필요하다. 참여하는 사람이 많아질수록 정보량이 많아 지는 것. 버너스 리는 웹의 이러한 잠재력을 발견하고 웹 기술을 일반인들도 무료로 마음껏 이용하게 한다. 이러한 이유 때문에 인터넷에서 웹이 폭발적으로 성장했고 그 속의 정보량도 무궁무진하게 많아졌다. 여기까지가 웹의 대략적인 역사다.
*팀 버너스 리가 어떤 계기로 웹을 만들었는지 알고 싶다면 아래 글을 한번 읽어보는 게 좋다. 영문이지만 가볍게 읽어볼 만 하다.
History of the Web(영문): https://webfoundation.org/about/vision/history-of-the-web/
History of the Web
Sir Tim Berners-Lee is a British computer scientist. He was born in London, and his parents were early computer scientists, working on one of the earliest compu
webfoundation.org
3. 일반인이 웹 서버를 구하는 법
다시 돌아가서 우리는 다른 사람들이 내 웹사이트를 검색할 수 있도록, 웹 서버에 내가 만든 HTML파일을 올려야 한다. 웹의 핵심기술을 3가지 배웠으니 이 용어를 사용해서 해야할 일을 표현해보면 이렇다.
- 파일을 업로드 할 웹서버를 어디서 하나 구해서 내 파일을 올린다.
- 클라이언트는 URL로 서버에 내가 원하는 파일을 가리키고 요청한다.
1. 파일을 업로드 할 웹서버를 어디서 하나 구한다.
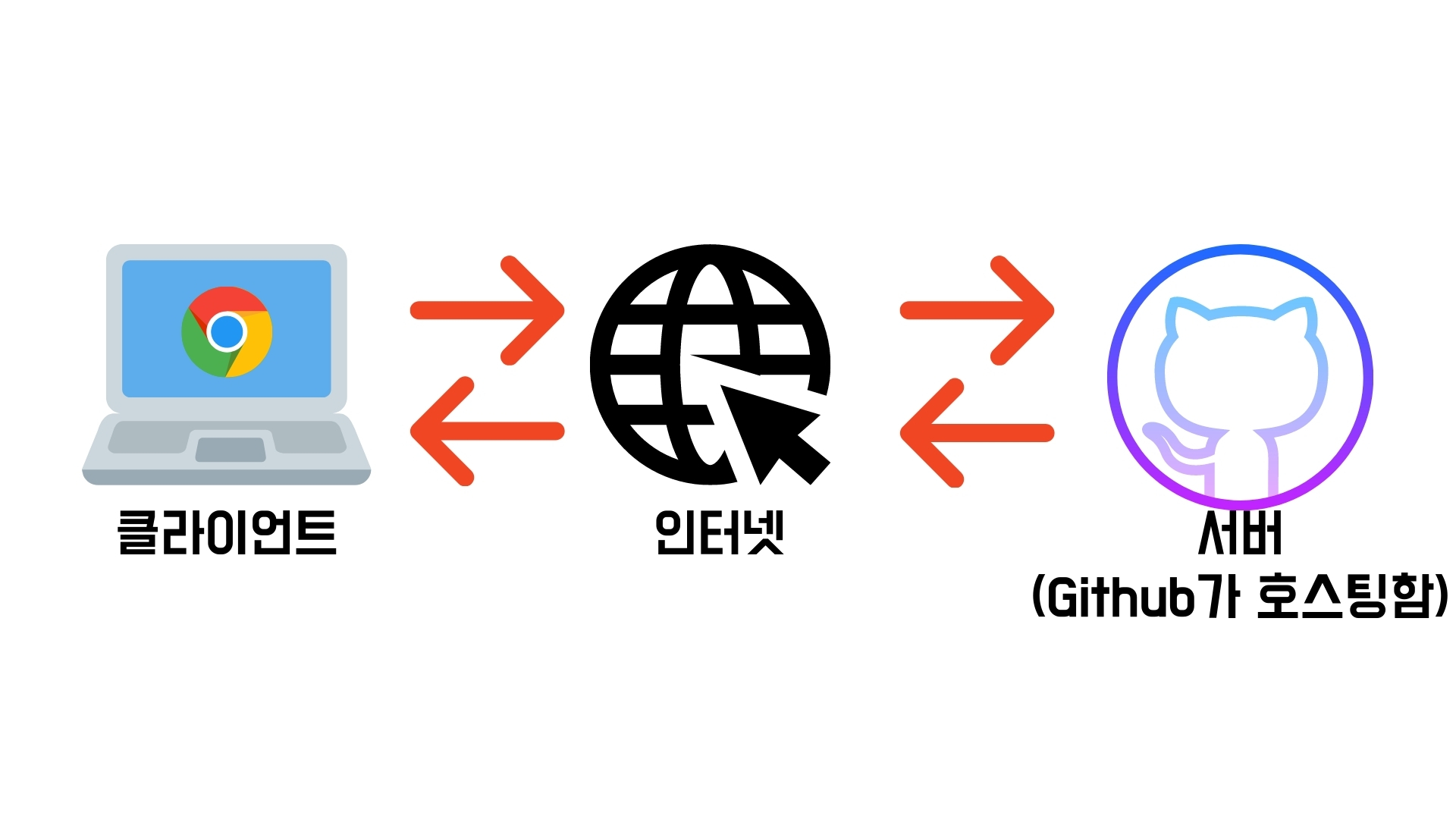
일반적으로 서버로 사용하는 장치는 미친듯이 비싸다. 근데 지금 우리는 서버에서 극히 일부의 저장공간만 필요하다. 다행스럽게도 서버의 일부분을 빌려주는 서비스가 존재한다. 이러한 서비스를 호스팅(hosting)이라고 한다. 호스팅을 전문으로 하는 업체들이 많이 있는데 안타깝게도 대부분 유료이다. 다행히도 Github라는 프로그래머 커뮤니티에서 자신이 만든 웹사이트 한 곳을 무료로 호스팅해준다.
웹 호스팅(생활코딩): https://opentutorials.org/course/3084/18891 참고
4. URL을 이용하여 서버에 있는 파일 접근하기
자 호스팅을 통해서 서버에 내 파일을 올렸다. 그럼 이제 웹 브라우저 검색을 통해서 내 웹사이트가 뜨는지 살펴봐야한다. 클라이언트는 URL로 서버에 내가 원하는 파일을 가리키고 요청한다. URL은 서버내 파일의 위치를 나타내는 방법이라고 아까 설명했다. 따라서 도서관에서 책을 찾는 색인과 유사하다. 방금 사용한 URL을 하나 가져왔다.

*https://opentutorials.org/course/3084/18891
https는 http에서 보안이 강화된 프로토콜이다. 과거 http의 단점을 보완했다는 정도만 일단 알아두자.
- :는 프로토콜 이름의 맨 뒤에 붙인다.
- //는 뒤에 도메인 이름(Domain name)이 필요할 때 붙인다. 도메인 이름이란 호스트의 이름을 말한다.
- opentutorials.org는 도메인의 이름이다. 옛날 옛적엔 도메인 이름 대신 IP주소만 들어갈 수 있었다. 저번 글에서 인터넷에 연결된 기계와 연락하기 위한 전화번호가 IP주소라고 언급했다. 즉 IP주소를 재정의 하면 호스트를 식별하는 고유번호이다. 근데 IP주소는 숫자로만 되어있어서 알아보기 어렵다. 그래서 IP주소를 알기 쉽게 다시 별명을 붙여준 것이 도메인 이름이다. 웹 브라우저는 우리가 입력한 도메인 이름을 DNS(Domain Name System, 도메인 이름들이 담겨있는 전화번호부 정도로 이해하면 된다)에서 IP주소로 찾아서 가져온다.
- /course/3084/18891는 파일에 접근하기 위한 경로(Path)이다. 여기까지 씀으로써 호스트 내에 있는 파일에 직접 도달할 수 있다.
URL의 요소를 구체적으로 알고 싶다면 아래 링크를 참고하길 바란다.
What is a URL?: https://developer.mozilla.org/ko/docs/Learn/Common_questions/What_is_a_URL
위에서 Github에 호스팅 된 나의 웹사이트도 똑같이 이런 방식 접근 가능하다. 이제 내 웹사이트가 정말 ‘웹’사이트가 되었다! 축하한다!

여기서 추가적으로 하나 더 해볼 일이 있다. 과연 내가 가진 이 PC도 서버가 될 수 있을까? 모든 호스트들은 서버가 될 수 있다. 당연하다. 다만 과정이 호스팅보다 복잡하고, PC가 꺼지면 서버도 꺼지는 셈이기 때문에 일반적으로 PC를 서버로 사용하진 않는다. 그 대신 이러한 과정을 해봄으로써 인터넷과 웹의 원리를 더 잘 이해할 수 있게 된다.
웹서버 운영(생활코딩): https://opentutorials.org/course/3084/18893 참고
이로써 인터넷과 웹이 돌아가는 원리, 그리고 그것들의 핵심기술들을 파악했다. 그리고 내 웹사이트를 만들어서 온라인 세상에 올릴 수 있게 되었다. 사실 상 HTML & Internet의 내용은 이 정도로 끝난다. 하지만 이쯤에서 우리가 과연 어느 정도의 안목을 갖게 되었을까? 확인해보는 것도 좋을 것 같다. 그래서 다음 번엔 웹사이트 탐방을 한번 가볼까 한다. 그래서 우리가 배운 것들을 복습해보고 과연 얼마나 성장했는지 알아보자.
*생활코딩 학습일기 카테고리의 글들은 모두 2021년, 제 이전 블로그에서 작성한 글입니다.
*정확한 정보를 전달하기 위해서 일부 내용은 수정하였습니다.
'생활코딩 학습일기(Web 기초)' 카테고리의 다른 글
| 6) 입문자가 알아야 할 CSS의 기본 특징 (0) | 2022.08.12 |
|---|---|
| 5) 웹페이지 탐방하기 (0) | 2022.08.11 |
| 3) 기본적인 웹사이트 만들기 (0) | 2022.08.11 |
| 2) 입문자를 위한 HTML 기초 (0) | 2022.08.09 |
| 1) Intro (0) | 2022.08.09 |



